多任务/多输出的高斯过程
对面多任务多输出的数据,我该怎么办?
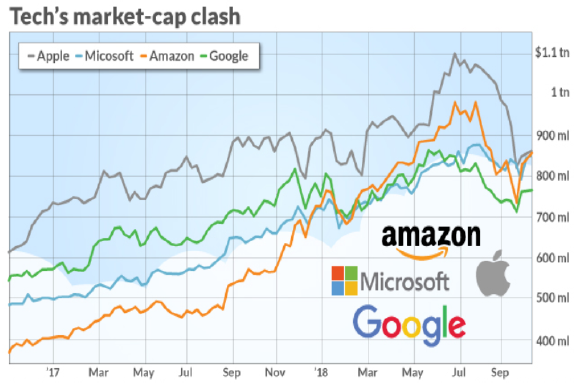 MOGP
MOGP话说已经好久木有更新文章啦,主线文章似乎有点动力不足,最近看着许多小伙伴对之前系列文章中一些问题,特地来写个答疑帖。这些问题总结来说其实主要是两个:
- “我的数据是这样的那样的,核心是多个序列,有一定相关性,我希望用高斯过程建模并且考虑,不知道可不可以?有什么好的代码包可以直接用吗?”
- “我的数据量好大,高斯过程模型好慢,有什么好的办法可以解决嘛?有什么好的代码包可以直接用吗?”
所以本文打算就这两个问题说说个人的一些想法与理解并且给一些推荐的文献,希望对大家有一些帮助。
在开始这些答疑帖之前,还是要先说明一下,这个【答疑解惑】系列是为那些对高斯过程模型已经有了一定了解的小伙伴(并且对概率论,测度论,泛函分析有一定基础知识)准备的,所以希望在你问问题之前可以先把之前通俗讲解高斯过程的一些文章过一遍,然后再看本文,或许“风味”才会更佳哈!
Okay,今天我们先来看看第一个问题吧!

下面让我们从宏观上的理解到具体的操作上来看看这个问题的一些子问题或者说是衍生问题吧!
1. 为什么我的多任务多输出模型表现的还没有单输出模型好呢?
在问这个问题之前,先问问大家“为什么我们需要多任务/多输出的模型?”
或许你会不假思索的回答:因为我们希望可以利用各个任务或者输出之间的关联性去构建一个更好的模型!其差别对比就如下图(图片来源参考文献[3])
这个答案本身非常简单,然而不知道各位小伙伴有没有相关这个答案背后的一些更深入的内容呢?
为什么这中所谓的关联性可以构建一个更好的模型呢?换句话说,如何才能确保多任务多输出模型利用的关联性对于模型构建是更好还是更坏呢?
It’s hard to say!
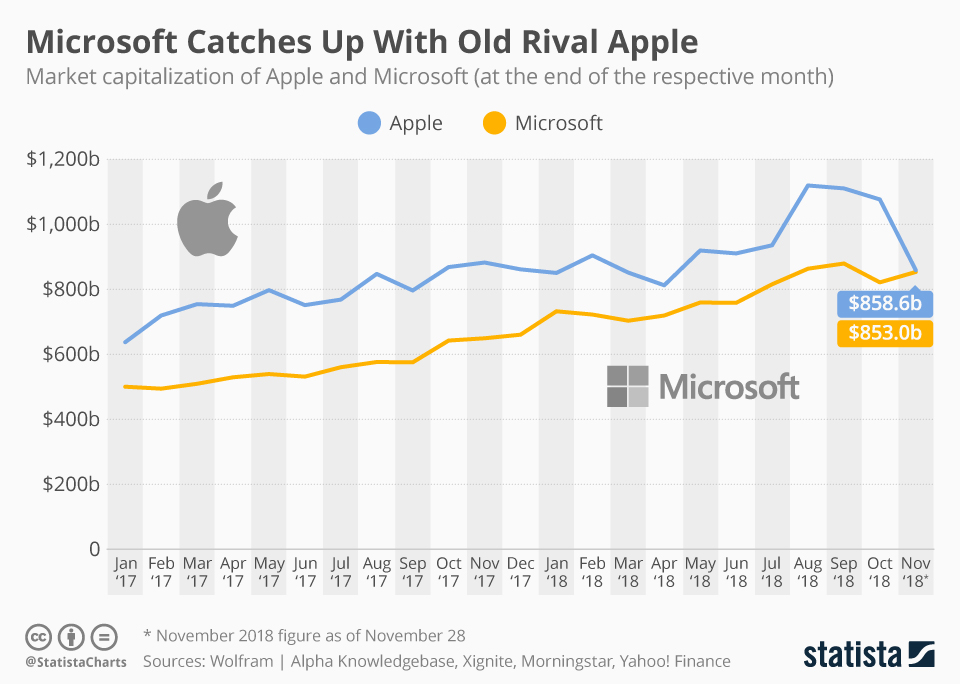
举个例子来说,比如微软和苹果的股票价格或者说是市值,你看看走势,再算算Pearson相关系数或者更高级一些的统计量,然后说okay,他们关联性很强,然后可以开始进行多任务多输出的建模,比如把微软和苹果的股票价格或者说是市值的历史数据放在一起,考虑多任务模型为未来进行预测,然后模型实现后发现,哦,果真如此,结果的确是有所提升,因为我们利用其相关性!
如果再仔细想一想更深入的话,什么是关联性很强呢?多强算是很强呢?是不是相关系数达到0.8以上就是很强呢?那么-0.8呢?是不是有些时候这种关联系会对模型造成干扰呢?如果相关系数约等于0的时候是不是说明这种关联性就等于没有关联性了呢?
当然你会设想,如果有一个general的多任务模型,不用管什么关联性,反正我是dependent的模型,即便事实是independent的话,也无非就是我的一个特例,所以建模,直接上数据,出结果不就好了么?
是的,没错,很多时候我们就是那么操作的!然而事实就是很很多的情况下,我们发现了一些所谓异常的情况:为什么我的多任务多输出模型表现的还没有单输出模型好呢?
为什么?为什么?
回到我们之前建模的时候,之所以我们要考虑多任务,我们的assumption或者说是expectation自然是我们以为多个序列数据之间的关联性是可以帮助我们提高模型效果的啦!而不是损害模型效果哦!
可是你有没有想过,或许我们这种assumption或者expectation是有问题的或者说是不切实际的呢?
毕竟没有那个研究从理论上证明过关联性的利用一定可以提高模型表现哦!因而我们也实在不知道到底什么时候这种关联性的利用会提高模型效果什么时候回损坏模型表现!
所以针对这个问题“为什么我的多任务多输出模型表现的还没有单输出模型好呢?”的回答以下几个可能:
- 因为假设不满足,所以我们的expectation是镜中花水中月!
- 因为你的模型不够好!
- 因为你的模型实现不够好!!
- 因为你的模型参数优化不够好!!!
- 因为你的代码写的不对!!!!
当然也有一些特殊的时候,那么上述第一种可能性会相对变小,而后面四种可能性会相对增加,因为我们的expectation变得更加有道理,我们更加坚信其中的道理。比如下面这个case,两个output共用一段input,并且两个output对应的input并不完全重合,即这两个outputs在不同点上都可以为彼此提供一些未知的信息[6]。
Evidence越充足,我们的Assumption就越强,对应的我们的Expectation也越有道理。
2. 高斯过程模型到底能不能处理多任务多输出的数据呢?
其实这个问题我们已经在上一个帖子中回答过了哈:
结论是:经典的高斯过程不能直接用于处理多任务/多输出的数据序列,但是采用一定的方式后可以使得高斯过程可以处理多任务/多输出的数据序列。
为什么呢?
下面我们结合上一篇帖子来深入讲讲这个问题。首先是
2.1. 经典的高斯过程不能处理多任务/多输出的数据系列
Why?
因为定义!因为高斯过程本质上是定义在实数空间$\mathbb{R}$上的哈。这件事情可以从两个角度来看,第一:高斯过程本质是个随机过程,自然可以从随机过程的视角来看。

因为其实一个随机过程可以看做是$S_T$-valued random variable,即所有可能的$S$-valued函数在任意$t \in T$上,其本质也是从$T$到$S$的映射[1]。而高斯过程作为其中的一个special case,其所对应的$T$其实并没有特殊要求,可以是一维空间也可以是多维空间。而所对应的$S$则是实数空间$\mathbb{R}$,也就是说,从函数空间的角度看,其刻画的是所有实函数的空间。
对应这点到data science, 自然经典意义下,它可以刻画的也就是实函数的特征性质。
当然第二,其实可以从更为深入的测度论来看,
高斯分布是高斯测度在实数$R$上诱导所得
多维高斯分布是高斯过程在空间$\mathbb{R}^d$上诱导所得
那什么是高斯过程呢?自然是高斯测度放在实值随机过程所在的空间啦!

这个详细可以参考文献[2].那么既然这是个实值随机过程,自然理论上是无法刻画多个序列的或者数据的关系的哈!
2.2 那么为什么又说,采用一定的方式后可以使得高斯过程可以处理多任务/多输出的数据序列呢?
这个“一定的方式”其实可以包括两个层面,第一,处理数据,即将多个任务多个序列的数据直接排成一列,假设其来自于一个实值函数空间,这样不就又满足高斯过程的定义了吗?只不过,现在我们需要考虑一个复合的kernel,即这个kernel的不仅需要考虑到相同任务对应不同input的关联,还要考虑不同任务之间的correlation而已。这条路是主流,绝大多数的研究都是follow这条路的,technically speaking,这里需要利用一些Kronecker production的东西。 就regression而来,这里有个非常棒的review[3],大家有兴趣可以看看一下哈。
这篇参考文献中还有个不错的分类图,下面就这个图我们来简单说说这个主流之路,详细请参考文献[3]:
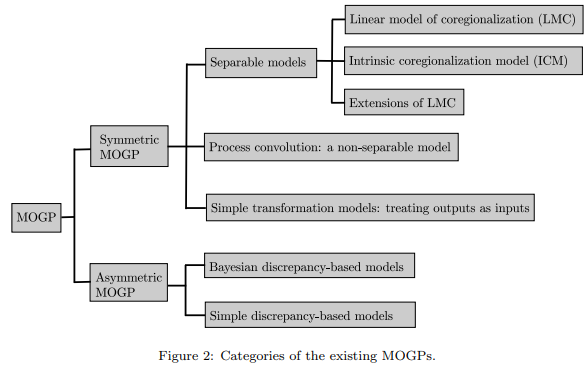
我们该如何用“一定方式”用高斯过程模型去处理多任务多输出的数据序列呢?
这里如上图所示,第一个方案是symmetric MOGP,第二个方案是asymmetric MOGP。
2.2.1 Symmetric MOGP
什么是symmetric MOGP呢?
这是说我们考虑各个output是同等地位的,比如考虑微软和苹果的股价或者市值的联合模型,自然我们应当将其放在同一地位。那么在这种case下,只要我们要做的就是用对称的covariance函数去捕捉不同output之间的共享信息。这点非常自然,毕竟covariance function本身就是对称的哈!
那么具体我们该如何去构建这样的symmetric MOGP的模型呢?
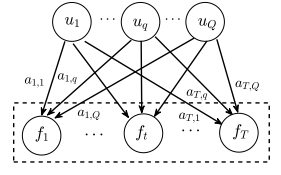
这里主要我们会考虑latent variable的形式,即用latent variable $u$或者说是一系列的$u$去刻画我们想要刻画的函数。这里最简单的就是线性的被称为linear model of coregionalization (LMC):
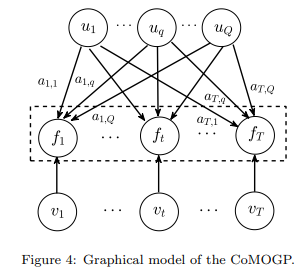
当然这里还可以更高级一点,即我们想要刻画函数除了具有这些共享信息的$u$提供信息之外,还有一些自身所独特的信息$v$,即CoMOGP模型:
当然再升级一下,就是把这一系列的$u$混合在一起去刻画我们想要的函数,这里可以使用就是卷积(当然这里这种非线性的混合方式也不一定是卷积,还可以是其他的哦!)
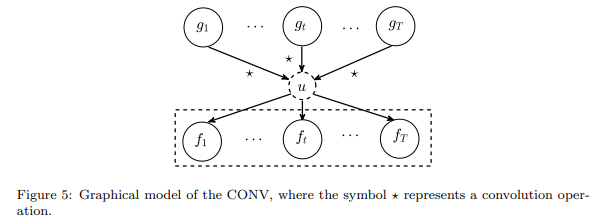
这里从kernel的具体表达形式看,前两者其实对应的kernel可以写成两个terms的separable的形式,但是后者这个卷积则不行(只能用积分表示),故我们称之为non-separable kernel.
其实除了之前说到latent variable的形式还可以更加的粗暴简单,即transform的思想,两步走,第一步,对单个output进行高斯过程建模,第二步,将所得到的output与原来的input放在一起(升高input的维度)再进行一次高斯过程的surrogate model。这个思路往下跑,可以更加复杂一些,Ensemble of regressor chains,一层一层地往下跑。。。。
这样的操作出发点是从工程的,所以对于实际问题或许有一定的效果,不过就模型表达而言,或许太过于粗暴简单没有明确的解释,当然也毫无美感,因而总体并不为大家所喜欢。
2.2.2 Asymmetric MOGP
与Symmetric对应的自然就是这个Asymmetric的形式啦,即各个output还不在同个level上。事实上这种例子也是不少,比如多层次多场景的情况(hierarchical multi-fidelity scenario), 这里多个output则是代表着对于同一个学习模型的不同层次不同场景情况。
这个类别下的Bayesian discrepancy-based models和 simple discrepancy-based models可以考虑,这里面具体的都相对复杂,但是核心其实是“层层递进”式的考虑。具体的可以参考review的文献[3],以及一些最新的研究方法,比如[4]。
2.3 除了将各个output排成一列去处理多任务多输出的数据序列,我们还有什么其他的选择?
当然除了将数据点排排坐使其满足高斯过程的定义条件,我们还可以让数据不动,升级高斯过程的定义,使其满足数据。当然这也不是主流!!!

该如何操作呢?
考虑到高斯过程是高斯测度放在实值随机过程所在的空间啦!那么想要实现多任务多输出且用高斯过程,那么我们可以升级高斯到多维高斯过程multivariate Gaussian Process (MV-GP),其实定义方式则可以参考高斯过程与高斯测度的等价定理,即,
多维高斯过程(MV-GP)是高斯测度放在向量值随机过程所在的空间即可!只不过现在这个MV-GP所以需要三个指标量($\mathbf{u}, k, \Lambda$)去控制,

以regression模型为例,目前先考虑最简单的case, 即所有outputs共用一组inputs(即对于每一个input,所有output都有数据)。现在我们不需要将数据向量化,而是直接将不同的output,放在不同列,然后让这个matrix来自一个MV-GP即可!
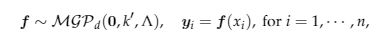
然后的操作就跟与最简单的GP一样啦,列出所有的数据点,在这里就是一个矩阵来自与矩阵高斯分布,然后有closed-form的表达式可以得到predictive distribution和marginal likelihood,然后利用极大似然估计就可以训练学习得到对应的超参数。
这里有一点需要注意的是,现在的超参数不光有$k$里面超参数,还包括这个用来刻画各个output之间correlation的超参数矩阵$\Lambda$,这里详细的可以参考文献[5].
另外这个思路下面,如果不打算用极大似然估计,自然也是考虑一些sparse的方法然后用变分贝叶斯去做推断。
不过回头想想这一条思路,目前为止,因为要放在一个matrix里面去,自然这里的一个大的局限就是要求数据share一组inputs,同时如果按照之前MOGP分类里面来说的话,因为MV-GP的定义中$k,\Lambda$的分离,所以这样的模型其实也只是考虑了separable的情况。
总的来说这条路表示简单,形式漂亮,但是就是局限性还是蛮大的,并且也非主流之选。
3. 多任务多输出的高斯过程模型该如何实现?或者说有木有推荐的代码包呢?
说到实现,讲实话,最好的肯定是自己亲自动手实现的模型,毕竟自己是对自己需求最了解的人,而已知的框架并不能在任何时候都满足你的需求。
当然,现实是这里有许许多多小伙伴都是工程导向的使用高斯过程模型而已,并没有特别大的动力去自己从头对高斯过程模型推到一边然后再去实现一遍,时间不允许,也不现实,其实也不是很有必要!
所以这里大家更关注的是:有木有推荐支持多输出的高斯过程代码包呢?
说到代码包,其实之前有一篇文章已经做了一些介绍了:
【番外篇】Gaussian process for machine learning实战学习资料推荐整理
就支持多任务多输出的高斯过程模型而言,这里在多说几句个编程语言下的简介,很多甚至都算不上推荐,仅仅是罗列而已,仅供参考!
3.1 Python
目前Python作为Machine Learning的主流工具,自然可用的轮子也是最多的。目前为止大家公认比较强大好用的是
- 【五星推荐】GPFlow
- 【五星推荐】[GPyTorch][https://gpytorch.ai/]
这两个都非常强大,两个各自基于目前主流的深度学习框架,TensorFlow和PyTorch。 只不过前者是脱胎于Sheffield早其的Python库 [GPy][https://sheffieldml.github.io/GPy/],偏重于spare模型与变分推断,后者则是更偏重于kernel以及基于low rank approximation的矩阵加速策略(这些具体的内容,我们会在下一个【答疑解惑】中详细说到)。另外这两个的区别还在于TensorFlow和PyTorch自身的特点,前者更适合大规模的部署,后者更容易上手。
至于其他的一些libraries,一般都是基于一些特定的multi-output方法作者自己给出的实现方式,比如:
3.2 Matlab/Octave
作为深受许多工科小伙伴喜爱的编程语言Matlab(Octave其实很多时候可以看做是开源的弱化版Matlab,语法是类似的)也有许多优秀GP代码包哈,这就包括经典的gpml包,不过遗憾的是gpml并没有支持多任务多输出的高斯过程。
在Matlab的语言下,仅次于gpml的一个library当属【四星推荐】[GPstuff][https://github.com/gpstuff-dev/gpstuff]啦,这是主要是芬兰阿尔托大学Jarno Vanhatalo and Aki Vehtari 主持维护的。里面有个demo介绍如何使用的,详见:[Link][https://github.com/gpstuff-dev/gpstuff/blob/develop/gp/demo_multivariategp.m]。
另外,基于第2.3章节中的策略,这里还有一个本人自己的Matlab包,
看在是自己的包,怎么说也要红着脸给个【一星推荐】哈!
不过实话来说,library不是非常稳定,而且速度也没有优化,只能说它基本实现了参考文献[5]中所叙述的模型罢了。不过之所以说是推荐,自然是博主对其每一个环节非常熟悉,如果小伙伴有任何问题,必定是知无不言言无不尽哈!
至于其他的一些libraries,也是基于一些特定的multi-output方法作者自己给出的实现方式,比如:
3.3 R
作为一个超级强大的开源编程语言,R自然是需要从统计出发的小伙伴所喜爱的编程语言,不过在高斯过程相关模型中却不是主流,当然仍然还是有一些的libraries大家可以参考的,多数是基于一些特定的multi-output方法作者自己给出的实现方式,比如:
- stmra
- etc
3.4 Julia
作为也一个新兴的机器学习所用的编程语言,这里也已经有了一些多高斯过程甚至多输出高斯过程的libraries啦, 比如:

以上大致就是的一些支持multi-output的libraries的罗列,其中但凡有【X星推荐】的包都是个人尝试过的,至于其他的一些就不知道。。。
大家有兴趣可以试试如果他们的文章的target正好就是你所想要的话,测试之后欢迎小伙伴们贡献自己的测评哦!
当然如果有小伙伴知道一些不错的library,也欢迎大家留言推荐哈!
Reference
[1] Kallenberg, Olav, and Olav Kallenberg. Foundations of modern probability. Vol. 2. New York: springer, 1997.
[2] Rajput, Balram S., and Stamatis Cambanis. “Gaussian processes and Gaussian measures.” The Annals of Mathematical Statistics (1972): 1944-1952.
[3] Liu, Haitao, Jianfei Cai, and Yew-Soon Ong. “Remarks on multi-output GaLiu, Haitao, Jianfei Cai, and Yew-Soon Ong. “Remarks on multi-output Gaussian process regression.” Knowledge-Based Systems 144 (2018): 102-121.
[4] Hamelijnck, Oliver, Theodoros Damoulas, Kangrui Wang, and Mark Girolami. “Multi-resolution multi-task Gaussian processes.” Advances in Neural Information Processing Systems 32 (2019): 14025-14035.
[5] Chen, Zexun, Jun Fan, and Kuo Wang. “Remarks on multivariate Gaussian Process.” arXiv preprint arXiv:2010.09830 (2020).
[6] Wang, Bo, and Tao Chen. “Gaussian process regression with multiple response variables.” Chemometrics and Intelligent Laboratory Systems 142 (2015): 159-165.
蓦风星吟
文艺小资的数学PhD/助理教授
Mathematics + Data + Me = Magic